
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- jQuery
- 탑다운
- 웹스크래핑
- addEventListener
- setItem
- topdown
- 자주 사용하는 Quaternion 함수
- 도트
- Lerp
- 회전
- PYTHON
- 독립변수
- vsCode
- Quaternion
- 도린이
- classList
- className
- 2D
- wsl
- Event
- 코딩
- intervals
- 픽셀
- 연습
- getItem
- euler
- click
- 종속변수
- Unity
- javascript
- Today
- Total
쫑가 과정
2주차 연습 - 쿠팡 웹스크래핑 본문
저번에 했던 분석을 토대로 실전을 해보자!
1. 쿠팡
기본적인 시작을 써준다.
웹페이지에 들어갈 url을 찾아오자
나는 고양이를 검색해서 나온 리스트를 가지고 오고 싶다!
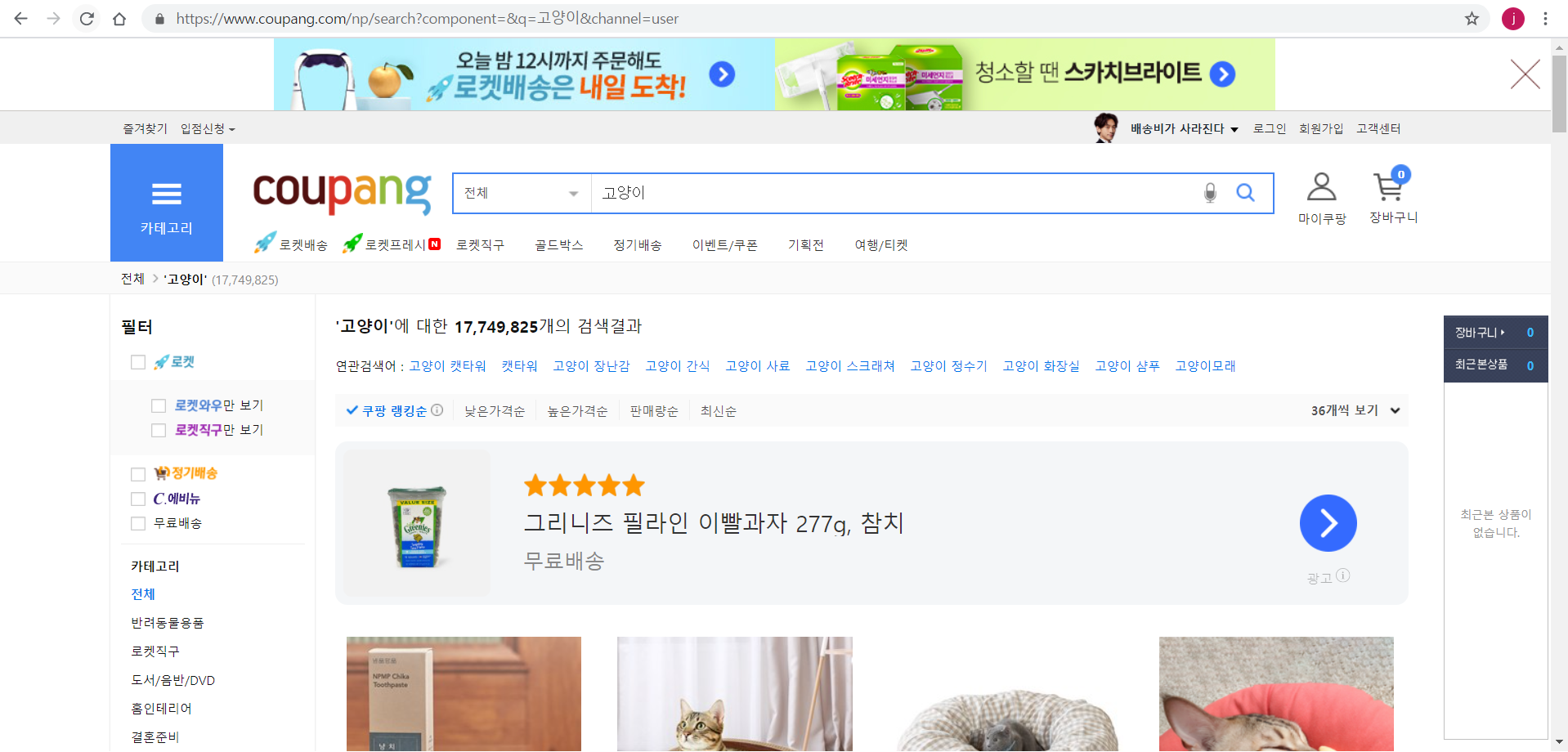
import requests
from bs4 import BeautifulSoup
#고양이를 검색해 나온 url
webpage = requests.get("https://www.coupang.com/np/search?component=&q=%EA%B3%A0%EC%96%91%EC%9D%B4&channel=user")
soup = BeautifulSoup(webpage.content, "html.parser")
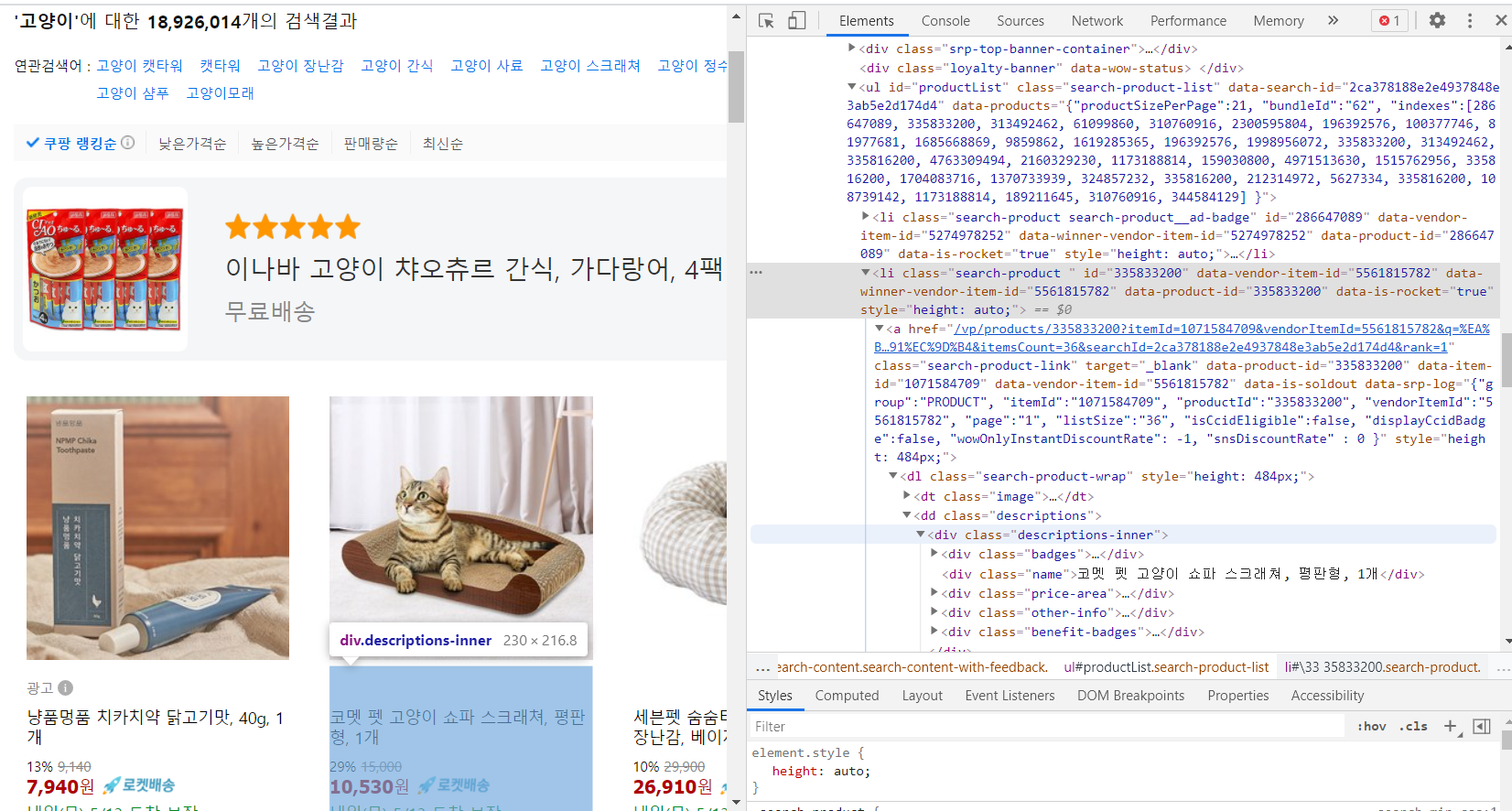
getItem = soup.select("ul#productList li")
# 이런식으로 크롤링이 안되는 경우에는 위에서 부터 찾아서
# select_one("#productList > li.search-product > a > dl.search-product-wrap > dd.descriptions > div.descriptions-inner")
# 이라는 메소드로 직접 찾아간다.
그다음 for 반복문을 돌려주면 된다.
for item in getItem:
item_name = item.select_one('div.name').text.strip()
item_price = item.select_one('strong.price-value').text.strip().replace(',', '')
item_link = base_url + item.select_one('a').get('href')
check_item_discount_rate = item.select_one('span.instant-discount-rate')
item_discount_rate = '할인 안함'
# 할인을 안하는 경우 None이 나와서 에러가 난다.
# 이럴때는 html이 규칙적이지 않다는 건데
# if 라는 조건문을 통해서 할인이 있는 경우만 가져오면 에러가 나지 않는다.
if check_item_discount_rate:
item_discount_rate = check_item_discount_rate.text.strip()
check_item_point = item.select_one('em.rating')
item_point = '없음'
if check_item_point:
item_point = item.select_one('em.rating').text.strip()
print(item_name)
print(item_price)
print(item_discount_rate)
print(item_link)
#별점이 숫자로만 되어있기 때문에 +점을 추가해줬다.
print(item_point + '점')
import requests
from bs4 import BeautifulSoup
#고양이를 검색해 나온 url
webpage = requests.get("https://www.coupang.com/np/search?component=&q=%EA%B3%A0%EC%96%91%EC%9D%B4&channel=user")
soup = BeautifulSoup(webpage.content, "html.parser")
getItem = soup.select("ul#productList li")
# 이런식으로 크롤링이 안되는 경우에는 위에서 부터 찾아서
# select_one("#productList > li.search-product > a > dl.search-product-wrap > dd.descriptions > div.descriptions-inner")
# 이라는 메소드로 직접 찾아간다.
base_url = 'https://coupang.com'
for item in getItem:
item_name = item.select_one('div.name').text.strip()
item_price = item.select_one('strong.price-value').text.strip().replace(',', '')
item_link = base_url + item.select_one('a').get('href')
check_item_discount_rate = item.select_one('span.instant-discount-rate')
item_discount_rate = '할인 안함'
# 할인을 안하는 경우 None이 나와서 에러가 난다.
# 이럴때는 html이 규칙적이지 않다는 건데
# if 라는 조건문을 통해서 할인이 있는 경우만 가져오면 에러가 나지 않는다.
if check_item_discount_rate:
item_discount_rate = check_item_discount_rate.text.strip()
check_item_point = item.select_one('em.rating')
item_point = '없음'
if check_item_point:
item_point = item.select_one('em.rating').text.strip()
#어떤 항목을 출력하는지 보기 쉽게하기위해 print를 따로 모았다
print(item_name)
print(item_price)
print(item_discount_rate)
print(item_link)
#별점이 숫자로만 되어있기 때문에 +점을 추가해줬다.
print(item_point + '점')하지만 쿠팡은 호락호락하게 수집되어주지 않는다.
왜냐하면 로봇으로 인식되어 허가해주지 않기 때문!
관련해서 robot.txt에 대해 꼭 알기 바란다!
limelightkr.co.kr/robots-txt-%EA%B7%B8%EA%B2%8C-%EB%AD%90%EC%A3%A0/
Robots.txt 그게 뭐죠? - 라임라이트 블로그
Robots.txt 파일이란 웹 크롤러(Web Crawlers)와 같은 착한 로봇들의 행동을 관리하는 것을 말합니다. 우리가 이 로봇들을…
limelightkr.co.kr
어쨌든 그래서 내가 로봇이 아니고 사람이라고 말해줘야 하는데
내 유저 정보를 적어준다
headers = {'User-Agent' : '유저정보'}
#header : 접속하는 사람,프로그램에 대한 정보를 담고있음.
#여러가지 항목이 들어갈 수 있기에 복수형태 headers
requests.get('url', headers = headers)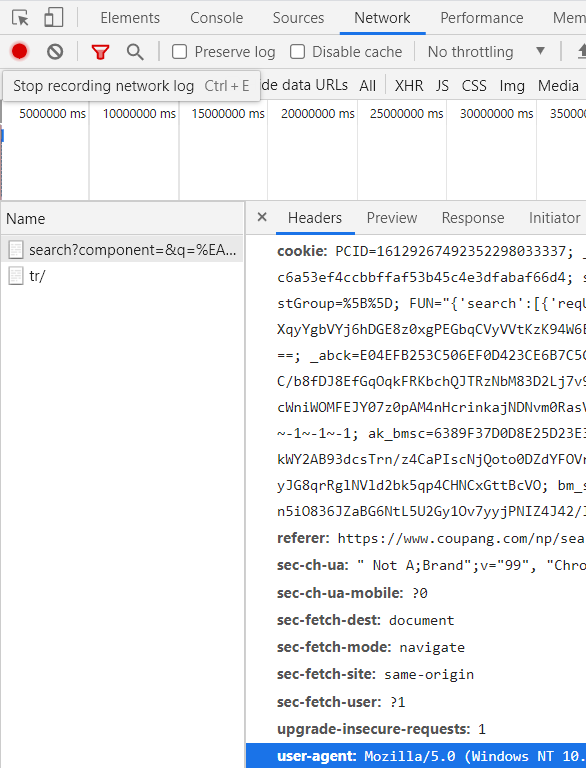
쿠팡 사이트에서 크롬- 검사항목(f12)을 누르고 Network에 들어가 웹페이지 새로고침(f5)을 해주면
현재 접속해 있는 주소 (search?...)가 name에 뜬다.
거기서 headers항목 -> 밑으로 내리면 user-agent:... 이 부분을 복사 붙여 넣기 하면 된다.
import requests
from bs4 import BeautifulSoup
headers = {'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/436.36"}
#고양이를 검색해 나온 url
webpage = requests.get("https://www.coupang.com/np/search?component=&q=%EA%B3%A0%EC%96%91%EC%9D%B4&channel=user", headers = headers)
soup = BeautifulSoup(webpage.content, "html.parser")
getItem = soup.select("ul#productList li")
# 이런식으로 크롤링이 안되는 경우에는 위에서 부터 찾아서
# select_one("#productList > li.search-product > a > dl.search-product-wrap > dd.descriptions > div.descriptions-inner")
# 이라는 메소드로 직접 찾아간다.
base_url = 'https://coupang.com'
for item in getItem:
item_name = item.select_one('div.name').text.strip()
item_price = item.select_one('strong.price-value').text.strip().replace(',', '')
item_link = base_url + item.select_one('a').get('href')
check_item_discount_rate = item.select_one('span.instant-discount-rate')
item_discount_rate = '할인 안함'
# 할인을 안하는 경우 None이 나와서 에러가 난다.
# 이럴때는 html이 규칙적이지 않다는 건데
# if 라는 조건문을 통해서 할인이 있는 경우만 가져오면 에러가 나지 않는다.
if check_item_discount_rate:
item_discount_rate = check_item_discount_rate.text.strip()
check_item_point = item.select_one('em.rating')
item_point = '없음'
if check_item_point:
item_point = item.select_one('em.rating').text.strip()
#어떤 항목을 출력하는지 보기 쉽게하기위해 print를 따로 모았다
print(item_name)
print(item_price)
print(item_discount_rate)
print(item_link)
#별점이 숫자로만 되어있기 때문에 +점을 추가해줬다.
print(item_point + '점')끝!
여기서 더 욕심을 내보자!
1페이지만 수집할게 아니라 여러 페이지를 수집해보자!

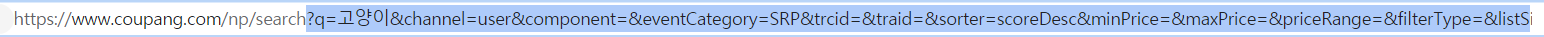
2페이지로 넘어갔을 때 url이다.
여기서 search? 뒷부분을 parameter라고 하는데 이 부분이 변경된 것을 볼 수 있다.
parameters는 headers 가장 밑 부분에서 찾아볼 수 있다.
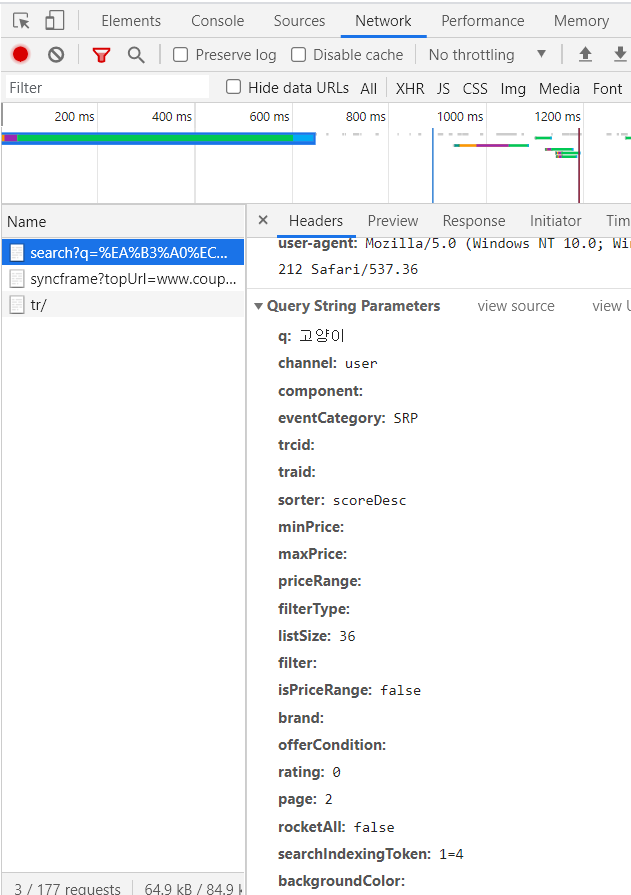

쭉 뒤로 가보니 page=2라고 적혀있는 부분이 보인다.
3페이지는 page=3인 거 보니 페이지 번호를 말하는 것을 알 수 있다.
이 부분을 이용해 보자.
지금 적은 코드는 현재 url페이지(1페이지)만을 수집한다.
내가 원하는 건 1페이지 수집 후 -> 2페이지 수집 후 -> 3페이지 수집 후 ->...
for 반복문에 range()를 사용해 숫자들을 차례로 불러 돌리면 되겠다.
docs.python.org/3/library/stdtypes.html#range
Built-in Types — Python 3.9.5 documentation
docs.python.org
# for 문 돌리기 - 반복문
# range => 범위 range(100) 0~99 숫자 백개
# range(n) 0 ~ n-1 숫자 n개
# index 0~ n~1
# for문이 한번 진행될 때마다 index +1
# for문은 range의 숫자가 다끝나면 n-1까지 돌아가면 종료
for index in range(2):
page = index+1
#parameter = params
params = {"page": page}range(2)라고 했기에 2페이지까지 수집한다.
이제 처음에 작성한 페이지 수집 후 출력하는 코드를 for index in range()에 포함시켜 반복시킨다.
import requests
from bs4 import BeautifulSoup
# for 문 돌리기 - 반복문
# range => 범위 range(100) 0~99 숫자 백개
# range(n) 0 ~ n-1 숫자 n개
# index 0~ n~1
# for문이 한번 진행될 때마다 index +1
# for문은 range의 숫자가 다끝나면 n-1까지 돌아가면 종료
for index in range(2):
page = index+1
#parameter = params
params = {"page": page}
headers = {'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/436.36"}
#고양이를 검색해 나온 url
webpage = requests.get("https://www.coupang.com/np/search?component=&q=%EA%B3%A0%EC%96%91%EC%9D%B4&channel=user", headers = headers)
soup = BeautifulSoup(webpage.content, "html.parser")
getItem = soup.select("ul#productList li")
# 이런식으로 크롤링이 안되는 경우에는 위에서 부터 찾아서
# select_one("#productList > li.search-product > a > dl.search-product-wrap > dd.descriptions > div.descriptions-inner")
# 이라는 메소드로 직접 찾아간다.
base_url = 'https://coupang.com'
for item in getItem:
item_name = item.select_one('div.name').text.strip()
item_price = item.select_one('strong.price-value').text.strip().replace(',', '')
item_link = base_url + item.select_one('a').get('href')
check_item_discount_rate = item.select_one('span.instant-discount-rate')
item_discount_rate = '할인 안함'
# 할인을 안하는 경우 None이 나와서 에러가 난다.
# 이럴때는 html이 규칙적이지 않다는 건데
# if 라는 조건문을 통해서 할인이 있는 경우만 가져오면 에러가 나지 않는다.
if check_item_discount_rate:
item_discount_rate = check_item_discount_rate.text.strip()
check_item_point = item.select_one('em.rating')
item_point = '없음'
if check_item_point:
item_point = item.select_one('em.rating').text.strip()
#어떤 항목을 출력하는지 보기 쉽게하기위해 print를 따로 모았다
print(item_name)
print(item_price)
print(item_discount_rate)
print(item_link)
#별점이 숫자로만 되어있기 때문에 +점을 추가해줬다.
print(item_point + '점')끝
+ 여기서 params를 이용해 코드를 좀 더 깔끔하게 만들어 보자.
for index in range(2):
page = index+1
params = {
"component": "",
"q": "고양이",
"channel": "user",
"page": page
}
headers = {'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/436.36"}
# component:
# q: % EB % 83 % 89 % EC % 9E % A5 % EA % B3 % A0
# channel: user
webpage = requests.get("https://www.coupang.com/np/search", headers=headers, params=params)이런 식으로 조금 더 보기 쉽게 만들 수 있다!
'프로그래밍 공부 > 파이선_정보취합하기' 카테고리의 다른 글
| 마치고. (2) | 2021.05.28 |
|---|---|
| 4주차 - wsl에서 selenium 인스타 정보 엑셀수집하기 (0) | 2021.05.28 |
| 3주차 - 쿠팡 정보를 엑셀로 만들기 (0) | 2021.05.20 |
| 7가지 연산자를 이용한 계산 실습 (0) | 2021.05.17 |
| Python 기초 이론 박살내기! (0) | 2021.05.17 |
| 2주차_쇼핑페이지 크롤링하기(X) (1) | 2021.05.04 |
| 1주차_윈도우 Visual Studio Code에 가상환경 설정! (0) | 2021.04.29 |
| 0. 코딩 (0) | 2021.04.22 |



